Graph Data Workspace Project

I wanted to fire up a little application to reinforce my understanding of both graph data and JSONSchema. It seemed like a worthwhile idea. Providing type definitions for nodes and edges seemed to make sense, since certain relationships (edges) only make sense between certain types of parties ( nodes ). I realized that could solve both these issues with JSONSchema by creating granular types for nodes an edges and organizing the compatible ones into 'dictionaries'.
This seemed like a fun challenge to adapt the abstract to the concrete and see what suffers in the process. Nothing this beautifully abstract ever survives when the rubber meets the road.
So, Why?
- Learn about JSONSchema use cases ( including as meta-schemas), graph data basics and d3 force-directed-graphs
- An exercise in abstraction
- Create something open-source to show as my work, accepting that software is really never complete. Most of my projects don't live past their 'minimum viable' stage, but are still useful or instructive in their simple form. I'm trying to avoid letting "perfect" be the enemy of "done".
Concepts
Here is how I imagined the concepts at a high level ( and some of this got done! ):
- Dictionary
- NodeTypes
- EdgeTypes
- Graph - uses one Dictionary
- Workspace - uses one Graph
- has own state ( orientation of nodes, pan & zoom of viewport, graph filtering )
- data updates are tracked and can be flattened to a new version of a Graph
Dictionaries are just directories containing schema files for nodes and edges that can exist within the same Graph. For example, the "Supply Chain" dictionary looks like this:
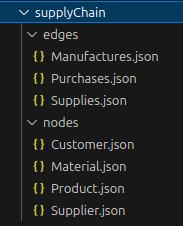
These schema all validate against schema/nodeTypeSchema and schema/edgeTypeSchema which allows the application to validate the dictionary.
Ideally these types are modular and could be re-composed into new dictionaries without much effort.
At this point I was going blind from staring at the syntax of my meta-schemas and was yearning to turn this into something realistic.
Many examples are too simplistic

Seeding my development graphs with synthetic data was an interesting diversion in learning about 'communities', 'bridges', 'centrality' and 'preferential attachment', however the generated data was only partially satisfying:

I tried to come up with some useful example dictionaries. Ultimately dictionaries/interpersonal ( for social networks ), dictionaries/forensic and dictionaries/supplyChain are the result of my efforts. This part was surprisingly time-consuming, but necessary to demonstrate the minimum viable use cases.
One Real Example
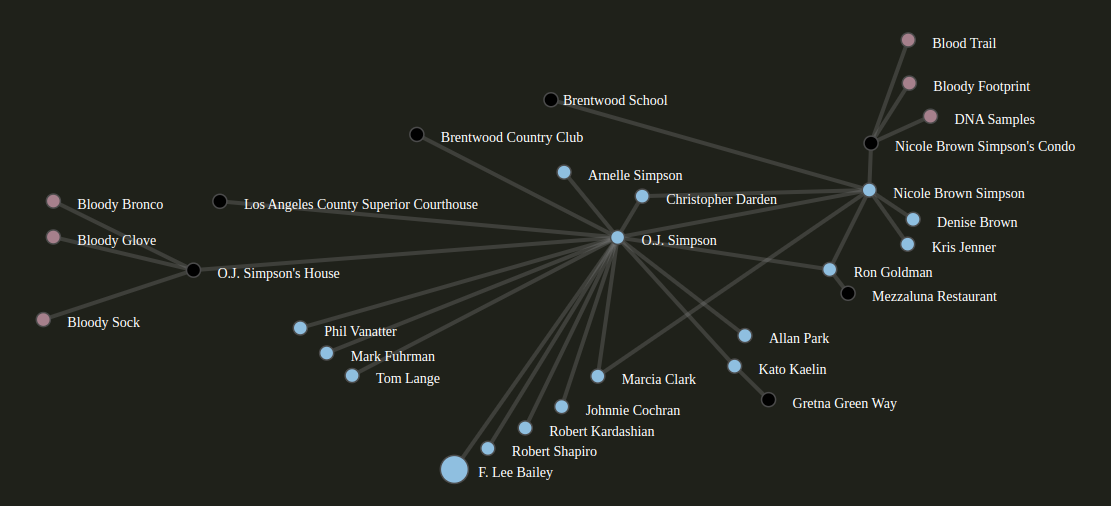
By pointing CoPilot to dictionaries/forensic I quickly generated this (approximate) topography of the O.J. Simpson case:
{
...
"nodes": [
{
"id": "person_nicole_brown_simpson",
"type": "Person",
"name": "Nicole Brown Simpson",
"description": "Victim, ex-wife of O.J. Simpson, found murdered at her Brentwood condo.",
"color": "#8FBFE0",
"gender": "female",
"occupation": "unknown",
"metadata": {}
},
{
"id": "person_ron_goldman",
"type": "Person",
"name": "Ron Goldman",
"description": "Victim, friend of Nicole Brown Simpson, found murdered at Bundy Drive.",
"color": "#8FBFE0",
"gender": "male",
"occupation": "waiter",
"metadata": {}
},
{
"id": "person_oj_simpson",
"type": "Person",
"name": "O.J. Simpson",
"description": "Former football star and actor, accused of the murders of Nicole and Ron.",
"color": "#8FBFE0",
"gender": "male",
"occupation": "actor and retired athlete",
"metadata": {}
},
...
"edges": [
{
"type": "Relationship",
"description": "Romantic relationship between O.J. Simpson and Nicole Brown Simpson, ending in divorce.",
"source": "person_oj_simpson",
"target": "person_nicole_brown_simpson",
"metadata": {},
"status": "inactive",
"relationshipType": "romantic"
},
{
"type": "Relationship",
"description": "Friendship between Nicole Brown Simpson and Ron Goldman.",
"source": "person_nicole_brown_simpson",
"target": "person_ron_goldman",
"metadata": {},
"status": "active",
"relationshipType": "friendship"
},
{
"type": "Relationship",
"description": "Rivalry between O.J. Simpson and Ron Goldman.",
"source": "person_oj_simpson",
"target": "person_ron_goldman",
"metadata": {},
"status": "active",
"relationshipType": "rivalry"
},
{
"type": "Link",
"description": "The bloody glove was found at O.J. Simpson's property.",
"source": "evidence_bloody_glove",
"target": "1",
"metadata": {},
"status": "inactive",
"relationshipType": "found_at"
},
...
]
}An excerpt of the data
Final Thoughts
This is neither a robust graph database engine nor a groundbreaking way of visualizing data, but I it does provide a simple framework for visualizing and understanding graph relationships. It could easily be extended to:
- Produce static visualizations highlighting specific elements or organization
- Visualize graph algorithms with annotations or animation
- Generate nearly-complete datasets with a few missing elements to simulate a problem to be solved
- Integrate with external data sources
- Expose an API for processing updates and distributing changes to update the visualization in connected clients
- Provide a UI for editing or annotating a graph
The actual frontend could use a few enhancements. Being able to edit nodes and edges through the UI would be great. Filtering the visualization ( hiding nodes and edges by type ) is also a really useful way to help understand the data. D3's graph visualization is fully interactive and I could be doing more to expose data upon hover / selection.